- Two
views on probability, compared with my lecture
notes
- My "a
priori" expectations are based on the expectations
without regard to advance empirical observations
(Schmidt, p. 217).
- His
"relative frequency" view ( p. 214) corresponds to my
"empirical" expectations.
- Know these
things
- Know
the addition rule of probability
- Know
the multiplication rule
- Understand
the notion of conditional probability for
non-exclusive events
- Understand
counting simple events
- Distinguish
between combinations (in which order of the
events or objects is irrelevant) from
permutations (for which unique orderings are
important).
- Note
that there is a formula for determining the number of
combinations of n objects taken r at a
time.
- Relevance
of all this:
- All
this stuff applies when, in practice, (1) you are
dealing with small categories of events and (2) small
numbers of cases.
- Usually,
it does not arise in social research, and I know very
few researchers who employ these formulas, but the
underlying ideas are important to understanding the
concept of probability.
- Schmidt's
summary on pages 242-243 is quite useful.
|
-
- Inferential
analysis uses the data you collected to report on data
you have not collected.
- It treats
your cases as a sample drawn to represent some
larger population.
- According
to rules of inferential analysis, you can infer
some facts about the population from your
sample.
- Inferential
statistics produces estimates of population facts
that range between specified intervals with stated
degrees of confidence or certainty in your
estimates.
- In
general, inferential statistics depends on carefully
drawn samples of cases:
- The
probability of selecting each case must be
known.
- The
simplest form of such probability sampling is
random sampling, in which each case has an
equal probability of selection.
-
Probability
distributions for DISCRETE v. CONTINUOUS
variables
- Computing
the probabilities of outcomes for discrete variables is a
complicated matter.
- Knowing
how to calculate these probabilities is important when
you are dealing with small numbers of cases: e.g.,
- voting
patterns on the Supreme Court
- success
of clinical treatments for small numbers of
patients
- passage
of a small number of bills introduced by a small
number of congressmen
- In each
instance, note the emphasis on small
- One
"rule of thumb" for what is "small" is under
30
- When
only a small number of cases is involved, the
probability of occurrence of each outcome is very
sensitive to each case and outcome.
- When
larger numbers of cases are involved, computations of
probabilities are simplified by using the BINOMIAL
THEOREM:
- This
states that the probability of r
successes,
- given
N independent trials with two
outcomes (called a Bernoulli experiment),
- is
the product of (a) the number of possible
sequences that have r successes,
- times
(b) the probability of each sequence.
- In
symbols, this is represented as:
- p(X
= r) =
nCrprqn-r
-
- The
important point is that as the number of trials (cases)
increases, the probability distribution assumes the shape
of the normal distribution.
- The normal
distribution approximates the binomial distribution, even
when N is very small. When N is 40 or larger, the
binomial distribution converges on the normal
distribution.
- Hence,
when the numbers of cases are large, one need not
calculate exact probabilities for discrete
outcomes.
|
Earlier
in the class, you encountered the normal
distribution. If you wish, go
here to review that
lecture.
|
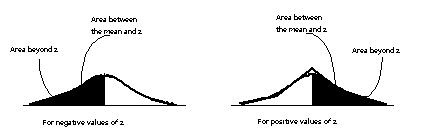
- Using
the Table of Areas under the Normal Curve: The
z-score
- You determine
the probability of occurrence of a random event
in a normal distribution by consulting a
table of areas under a normal
curve.
- Tables of the
normal curve are devised to have a mean of
0 and a standard deviation of 1.
- (e.g.,
Appendix 1, Table A, distributed with the
Schmidt chapter).
- To use any
table of the normal curve, you must convert your
data to have a mean of 0 and standard deviation
of 1.
- This is done by
transforming your raw values into
z-scores, according to this
formula:
- z-score
=
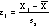
- Using
z-scores to read a table of areas under the
normal curve
-
Computational Examples of
z-scores:
|
Example:
percent black in Washington, D.C. in
1980 (Note: not 1990)
|
|
D.C's
Raw score = 70.3
|
|
|
|
Mean
for all states = 10.3
|
|
|
|
|
(70.3
- 10.3) = 60
|
60
/ 12.5 = 4.8
|
|
|
standard
deviation = 12.5
|
|
|
|
z-score
for D.C. = 4.8
|
|
Example:
D.C.'s percent vote for Reagan in
1984
|
|
D.C's
Raw score = 13
|
|
|
|
Mean
for all states = 60
|
|
|
|
|
(13
- 60) = 47
|
47
/ 8.8 = -5.3
|
|
|
standard
deviation = 8.8
|
|
|
|
z-score
for D.C. = -5.3
|
|
Comparison
with Florida: percent vote for Reagan in
1984
|
|
Florida's
percent black is 13.8
|
|
|
|
z-score
= (13.8 - 10.3) / 12.5 =
.28
|
|
Florida's
percent for Reagan was 65
|
|
|
|
z-score
= (65 - 60) / 8.8 = .57
|
|
Computing z-scores for raw data
- Transforming
raw standardizes the data, which makes it
easier to compare values in different
distributions.
- Limitations of
raw data values
- Raw scores
of individual cases do not disclose how they
vary from the central tendency of the
distribution
- One needs to
know also the mean of the distribution and
its variability to determine if any given
score is "far" from the mean
- Properties of
the z-score transformation
- It is a
linear transformation: does not alter
relative positions of observations in the
distribution nor change the shape of the
original distribution.
- The
transformed observations have positive
and negative decimal values
expressed in standard deviation
units.
- The
sign of the z-score tells whether
the observation is above or below the
mean.
- The
value of the z-score tells how far
above or below it is.
- When
transformed into z-scores, all distributions are
standardized
- The
mean of the transformed distribution
is 0.
- The
standard deviation of the distribution
is 1.
- The
variance of the distribution is
1.
- When subjected
to a z-score transformation, any set of raw
scores that conform to a normal distribution,
will conform exactly to the table of areas under
the normal curve.
- That is, the
likelihood of observing z-scores of
certain magnitudes can be read directly from a
Table of Areas under the Normal
Curve.
|
|